Passive Walker RL — Curriculum-Driven Biped Locomotion in JAX & Brax
A three-stage pipeline (≤ 300 LoC per stage) that bootstraps a passive-dynamic biped from a finite-state expert to a GPU-scale PPO policy in minutes. MuJoCo supplies fidelity; Brax pushes > 1 M env-steps s⁻¹ for massive sweeps, yielding smooth, sample-efficient walking with a single 1 M-param network.
Source Code Full Report Slides
1 · Overview & Motivation
Problem statement — How can a passive-dynamic biped learn a stable downhill gait in fewer than 10⁶ simulation steps on commodity hardware?
Bipedal walking is an under-actuated, contact-rich control problem; naïve RL burns millions of samples.
Passive Walker RL solves this with a three-component curriculum, each ≤ 300 lines of code, executed end-to-end in JAX.
| Stage | Engine & Size | Core Idea | One-Sentence Takeaway | Wall-Clock † |
|---|---|---|---|---|
| Finite-State Expert | MuJoCo XML · 100 LoC | Hip swing ±0.3 rad, knees retract on contact | Generates ≈ 30 k fault-tolerant demos in 30 s | < 30 s |
| Behaviour Cloning | 2-layer MLP (~10 k params) · Equinox | Supervised fit (MSE / Huber / L1) from 11-D proprio to 3 joint targets | Delivers a “walk-from-boot” policy scoring 0.26 Δx step⁻¹ | 2–3 min (CPU) |
| PPO Fine-Tuning | Brax 2 · Optax | BC-initialised actor + critic, imitation loss β(t)→0 | Reaches steady gait in 10⁵ steps, 5× faster than scratch | 8 min (RTX 4060 Ti) |
† Measured on AMD Ryzen 7 5800H + RTX 4060 Ti, physics Δt = 1 ms.
- Why it matters
- Curriculum beats brute force (an order-of-magnitude fewer samples);
MuJoCo fidelity + Brax speed (> 1 M env-steps s⁻¹);
Compact yet expressive (1 M-param policy);
Reproducible (hash-named artefacts, one-command replay);
Open (≈ 6 k LoC, MIT).
2 · Physics Model & Environment
The walker (Fig. 1) is a five-body planar biped with seven DoF—slide-x, slide-z, yaw, one hip hinge, two prismatic knees—walking down an 11.5° virtual slope.
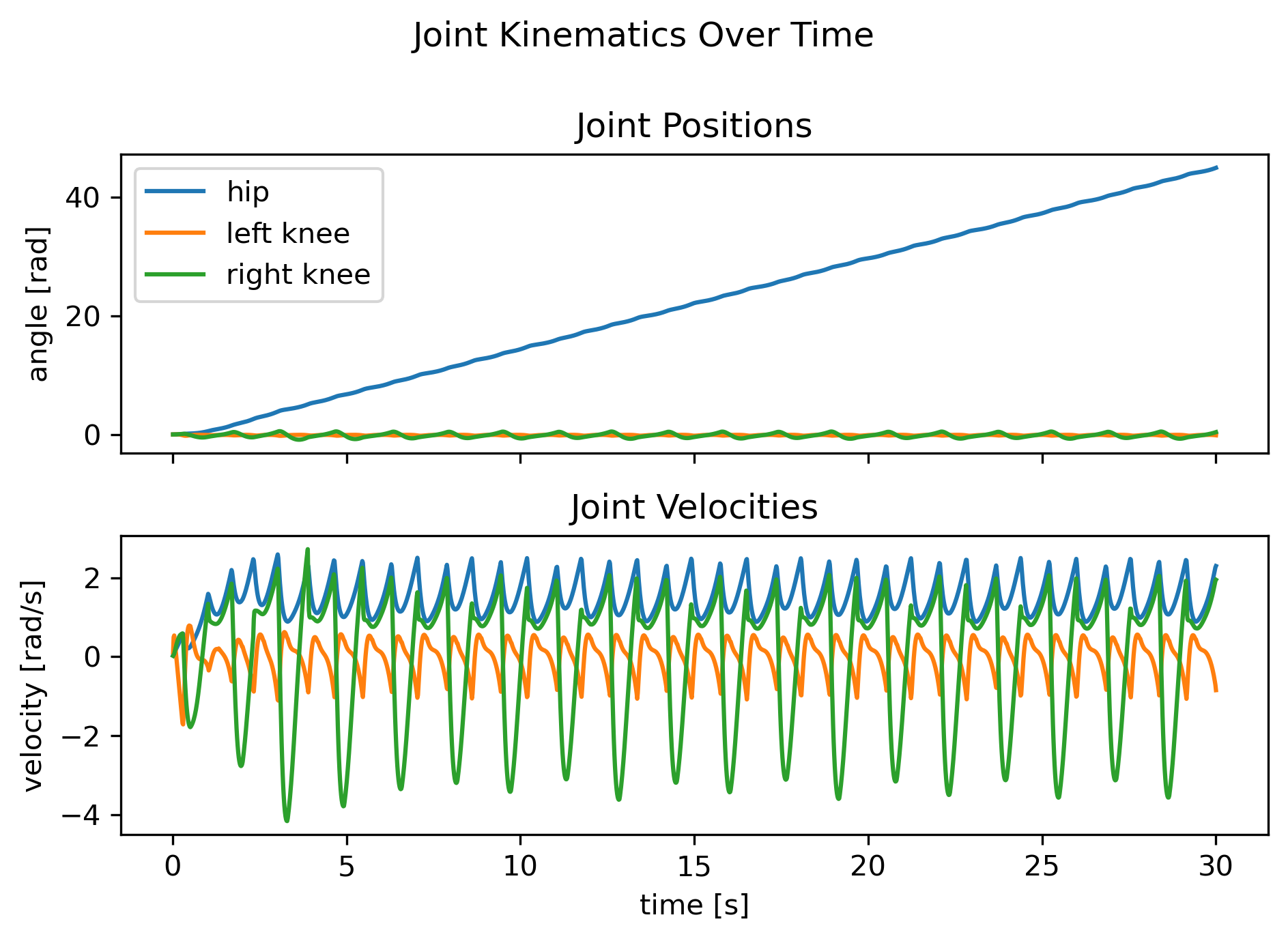 | 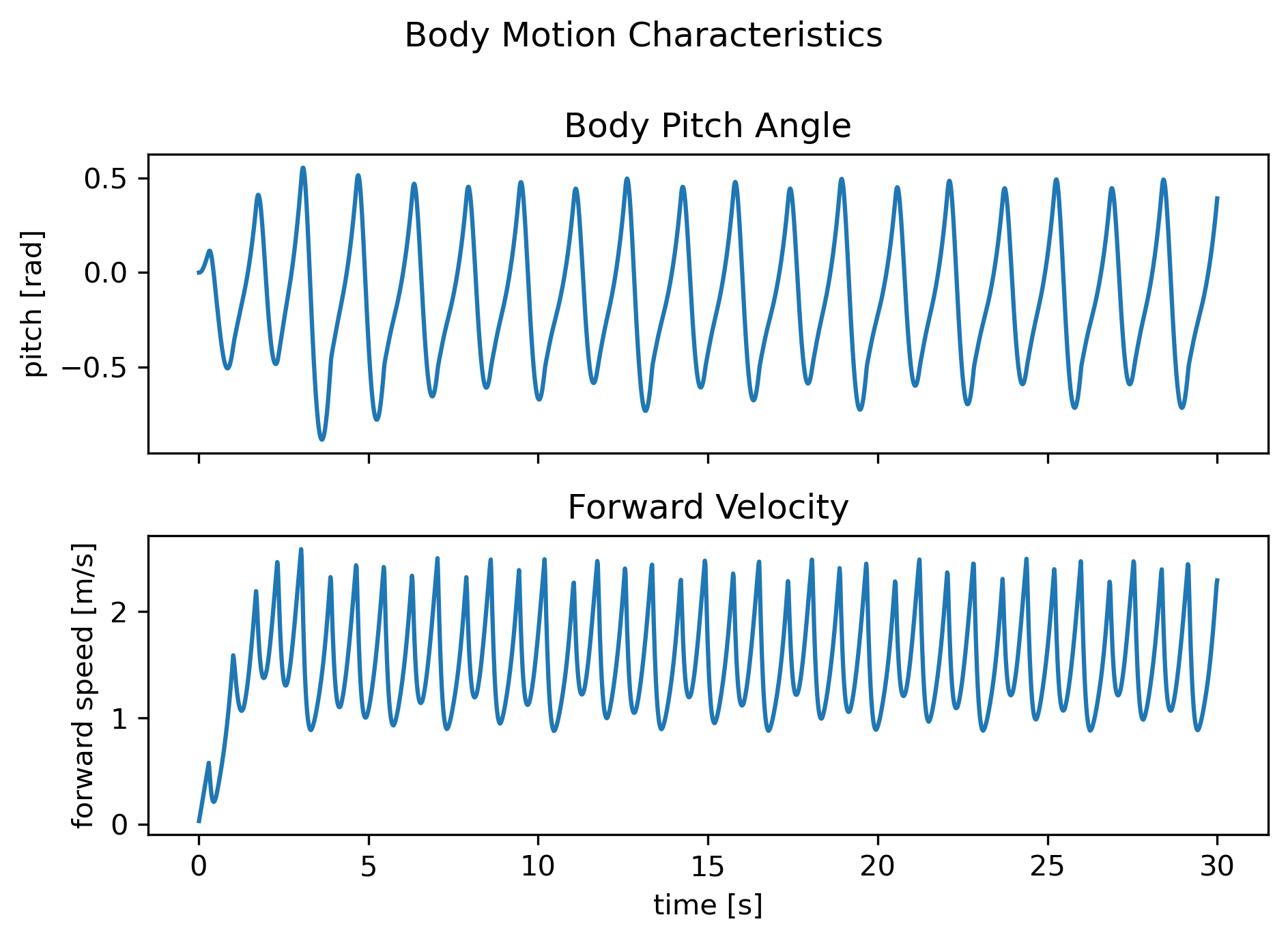 |
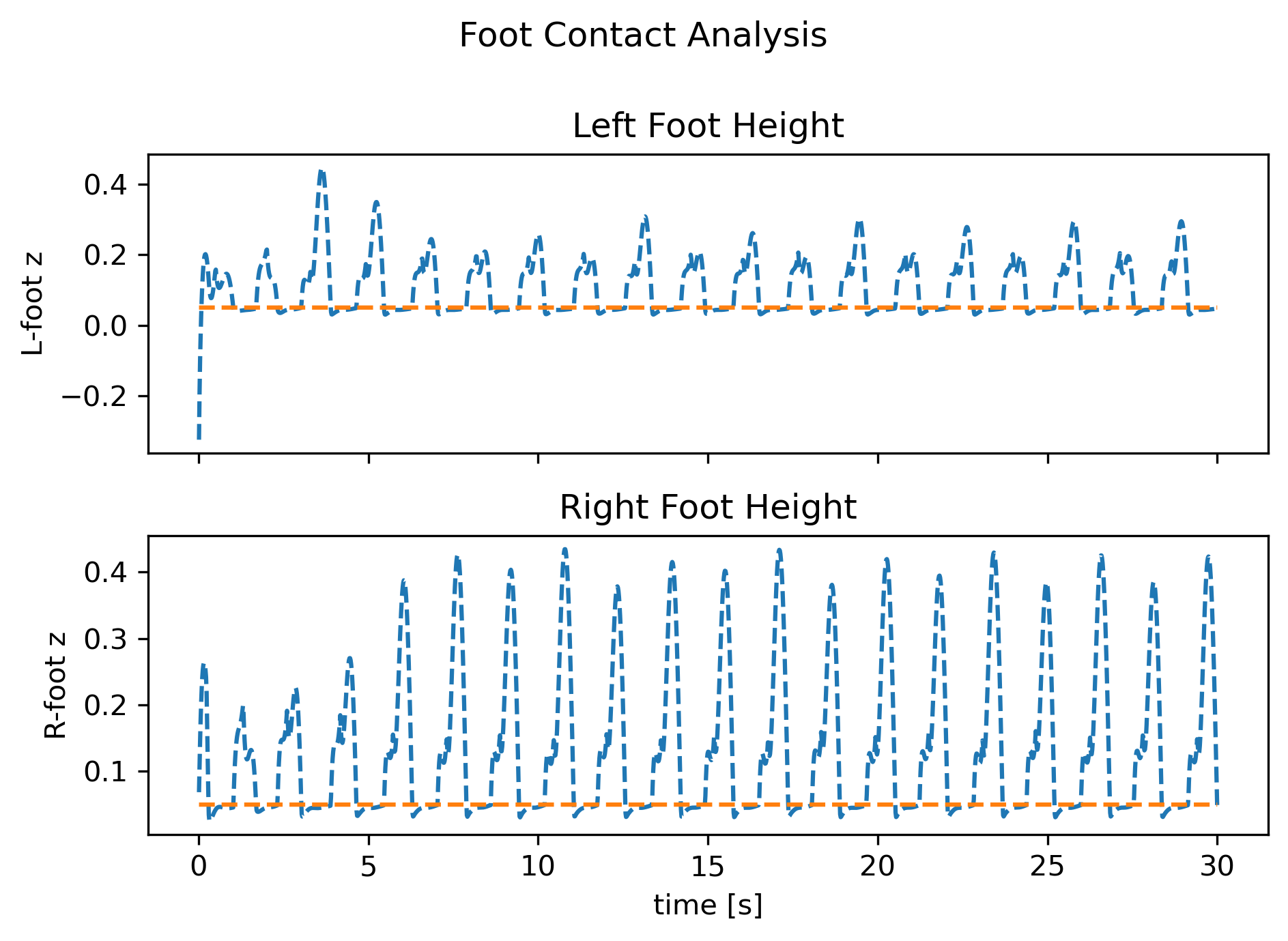 | 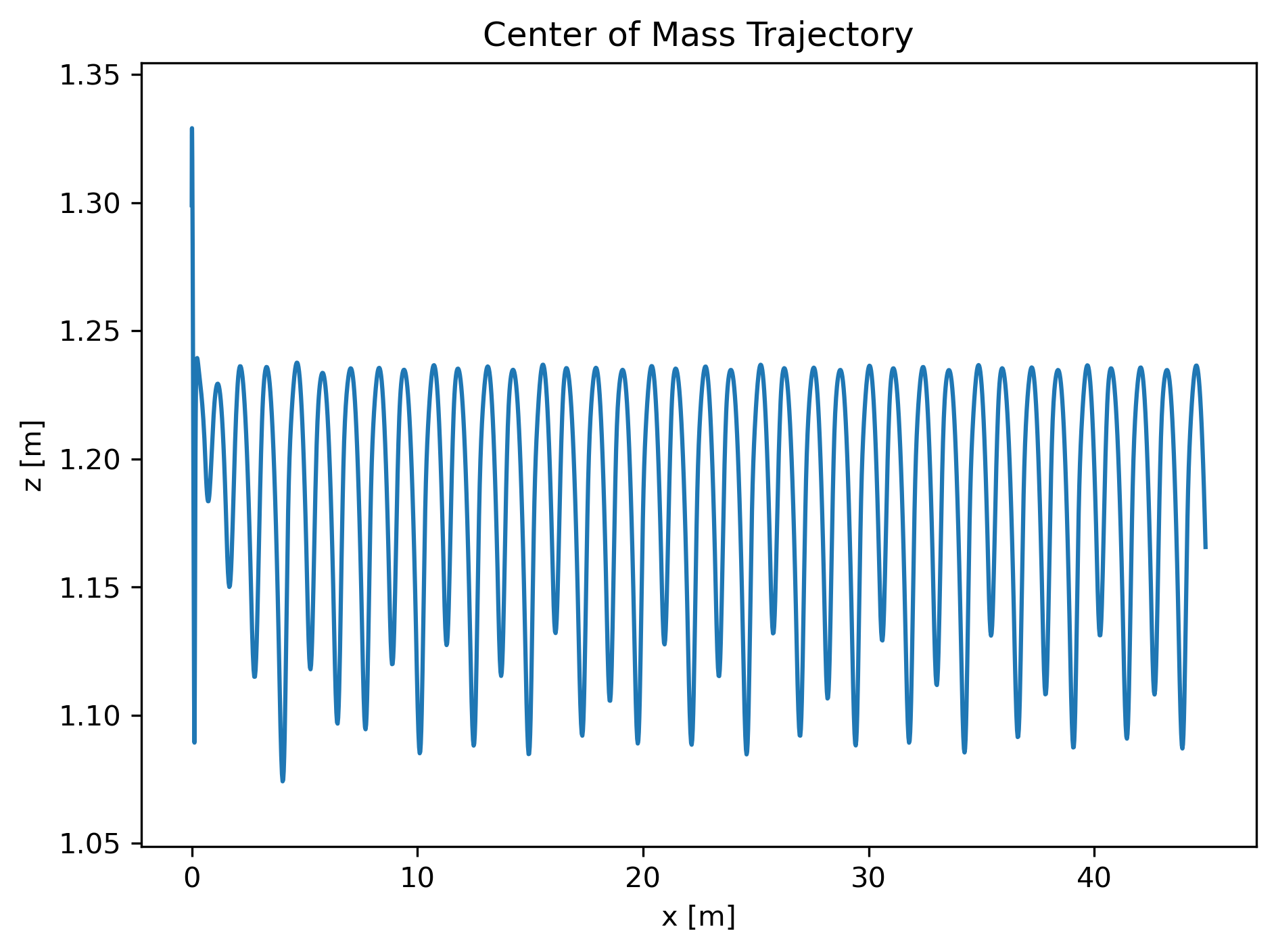 |
Fig. 1 — Finite-state expert trajectories: cyclic joint timing, stable torso pitch, periodic CoM track.
3 · Curriculum Stages
3.1 Finite-State Expert
Two hip states and a knee retraction FSM produce demonstrations at 1 kHz; ≈ 30 000 state-action pairs per run.
3.2 Behaviour Cloning
Observation Vector (11 Dimensions) Each timestep provides the following standardized features:
- Positional state:
x,z, torso pitch angle - Velocities:
ẋ,ż, hip angular velocity, knee linear velocities - Joint positions: hip angle, left/right knee extensions
- Joint velocities: hip q̇, left/right knee q̇
All features are extracted from MuJoCo in physical units and z-score normalised (zero mean, unit variance).
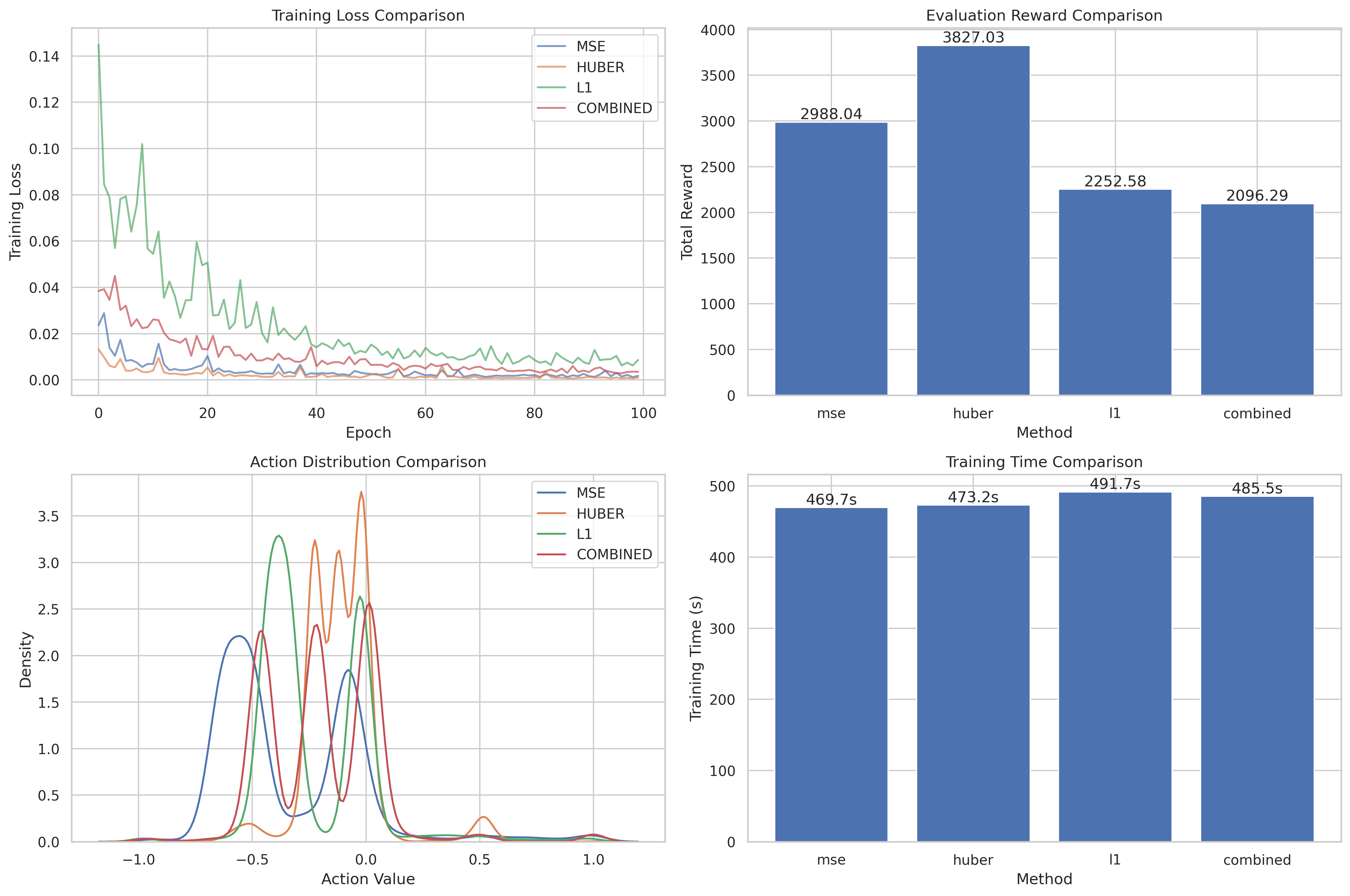
Figure 3 — Performance comparison of behaviour cloning variants across loss types.
Table 1 — Final MSE and Reward for Each Loss Variant
| Loss Function | Final MSE | Mean Δx per Step |
|---|---|---|
| MSE | 4.7 × 10⁻⁴ | 0.25 |
| Huber | 5.0 × 10⁻⁴ | 0.26 |
| L1 | 7.1 × 10⁻⁴ | 0.23 |
| Combined (Avg) | 5.4 × 10⁻⁴ | 0.25 |
Huber loss achieved the best trade-off, yielding the highest downstream reward despite slightly higher MSE.
3.3 PPO Fine-Tuning
Reward function (rt = x{t+1} - xt) (forward progress).
_Termination — episode ends if
- torso z < 0.5 m (height drop), or
- |pitch| > 0.8 rad (excessive tilt).
PPO hyper-parameters:
| Parameter | Value | Notes |
|---|---|---|
| γ | 0.99 | discount |
| λ | 0.95 | GAE |
| ε | 0.2 | clip |
| Entropy cost | 0.01 | exploration |
| Batch | 64 | update minibatch |
| Roll-out length | 128 | per env |
| Actor LR | 1e-3 | best in sweep |
4 · Brax Vectorisation & Hyper-parameter Sweep
convert_xml.py freezes the MJCF into System.pkl.gz; jax.vmap batches 128–1024 walkers → > 1 M env-steps s⁻¹.
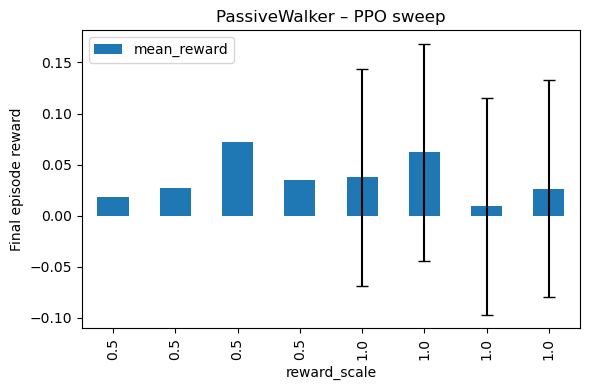 | 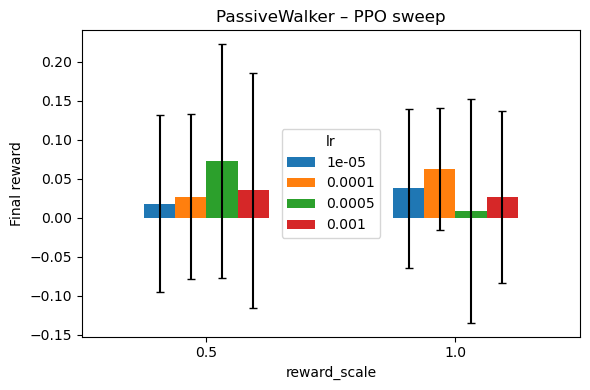 |
Fig. 2 — 120-run grid shows a sweet-spot: reward-scale 0.5, LR 1e-3, “medium” (~1 M params) network.
5 · Results
| Metric | BC-Seeded PPO | Scratch PPO |
|---|---|---|
| Steps to first stable gait | 1 × 10⁵ | 5 × 10⁵ |
| Final mean Δx step⁻¹ | 0.28 ± 0.02 | 0.24 ± 0.05 |
| GPU wall-clock | ≈ 8 min | 25 min |
Video 1 — 30-second deterministic MuJoCo replay using the best Brax-trained policy (no falls).
6 · Reproduce It (One Command)
python -m passive_walker.ppo.bc_init.run_pipeline \
--init results/bc/hip_knee_mse/policy_1000hz.eqx \
--device gpu \
--total-steps 5000000 \
--hz 1000
All artefacts land in results/passive_walker_rl/<timestamp>/ with SHA-256 config hashes.
7 · Future Work
- Uneven-terrain randomisation for sim-to-real
- Energy-aware rewards to penalise torque peaks
- TPU
pmaptraining for > 10 M env-steps s⁻¹ - Hardware validation on a planar biped rig